赛优市场店员积累了丰富的神秘顾客经验,严谨,务实,公平,客观.真实的数据支持!


发布日期:2024-03-07 13:10 点击次数:116
一切都有了更大的可能性。Sora一出上海暗访调查,诸多创业公司的红运因之转换。
我们最近外传了个超等戏剧性的故事,就在中国,就是中关村的一家创业公司:
Sora出世前,他们拿着一篇如今被ICLR 2024接纳的论文,十分良友地为投资东说念主、肆业者讲了泰半年,却处处碰壁。
春节后,打电话来约见团队的投资东说念主排起了长队,都是要学习Sora、学习团队论文效果。
为什么?
谜底很陋劣,Sora蓝本就是新晋顶流,再一次躬行实际了scaling law的正确可行。
更何况Sora背后的架构,与这支团队快1年前发表的论文建议的基于Transformer的Video妥协生成框架,大、撞、车。
撞车到什么进程呢?用团队本人的话来说,“不错说是确凿一模一样,嗯,就还得仔细地找到底那处不同”。
敢这样讲话,有点真谛。
要知说念,国内诸多团队都在通往AGI的说念路上苦苦教育,但许多东说念主于今如故很不看好国内团队的工夫翻新武艺。如果事实真像团队所说,那这就是国内军队有实力作念最前沿翻新的实质诠释。
于是,量子位得知后,火速研究上这个团队,带着民众第一时分把撞车瓜透彻吃透。
(淡淡剧透一下,其后我们发现跟Sora撞车这个瓜背后,还有更戏剧的故事)

谁在和OpenAI“撞车”?
不卖关子,和OpenAI“撞车”的这家初创公司,恰是成就于2021年的智子引擎。
而在它的身上,有太多的属性和标签值得说说念说说念。
90后CEO:由中国东说念主民大学高瓴东说念主工智能学院博士生高一钊创立。
东说念主大系:中枢团队成员多量来自东说念主大,何况由高瓴东说念主工智能学院卢志武教悔担任参谋人一职。
多模态大模子:公司成就之际大语言模子依旧是主流,却早早打入多模态这条“无东说念主区”的赛说念。
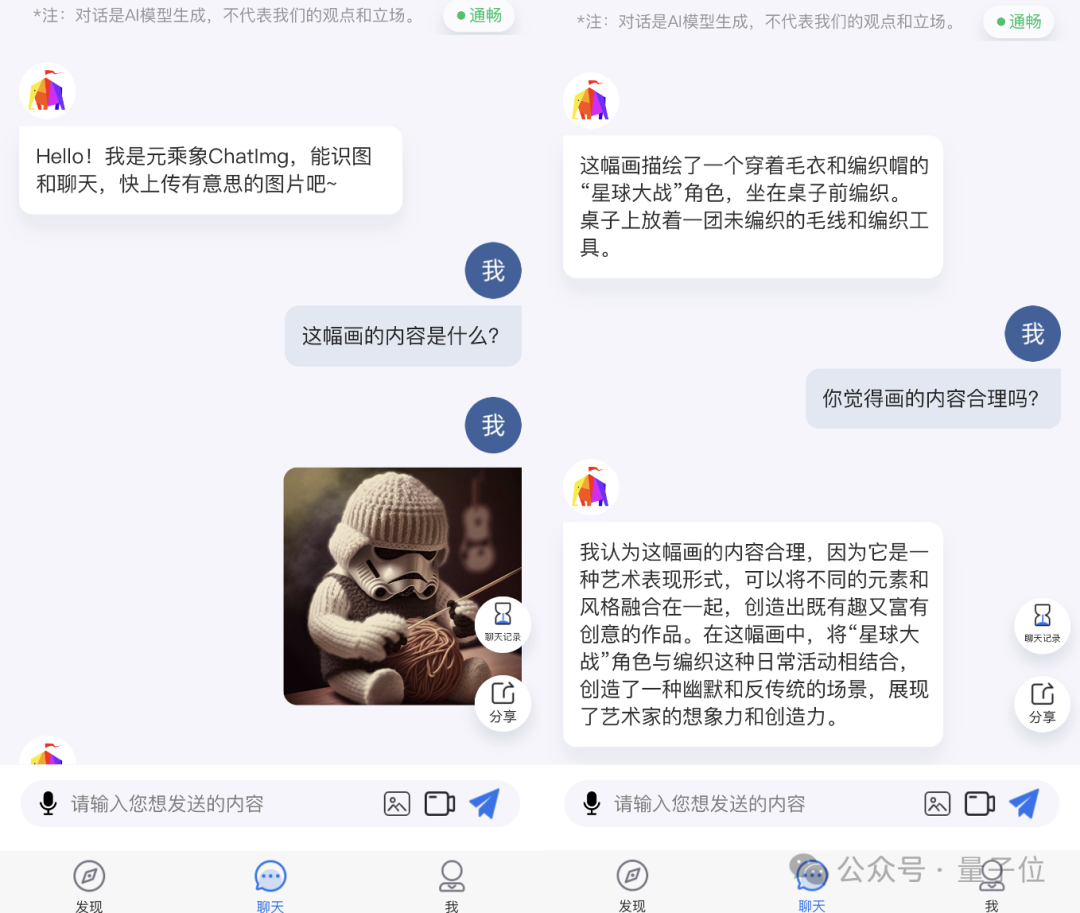
从刻下智子引擎所交出的“功课”来看,最为扫视当属于2023年3月发布的天下首个公开评测多模态对话应用ChatImg(元乘象),何况还是迭代到了3.5版块。
举例给ChatImg速即投喂一张图片,它不错立即用看图讲话,用笔墨精确描摹图片中的内容。
而且在问及不雅点性问题时,举例“是否合理”,ChatImg的复兴亦然近乎接近东说念主类的透露。
至于刚才提到与Sora“撞车”的论文,恰是由这家“东说念主大系”初创领衔,并连系伯克利、港大等单元于2023年5月发表在arXiv上的VDT。

在我们与卢志武教悔交流经由中,他这样描摹看到Sora工夫申诉后的感受:
像,实在是太像了。
因为Sora在工夫架构上所接受的是Diffusion Transformer,这是区别于以往文生视频(基于Stable Diffusion等)使命的重要点之一。
而仅从VDT论文的标题中,我们就不难发现,智子引擎在工夫架构上早已建议并接受了Diffusion Transformer,而且是首发的那种。
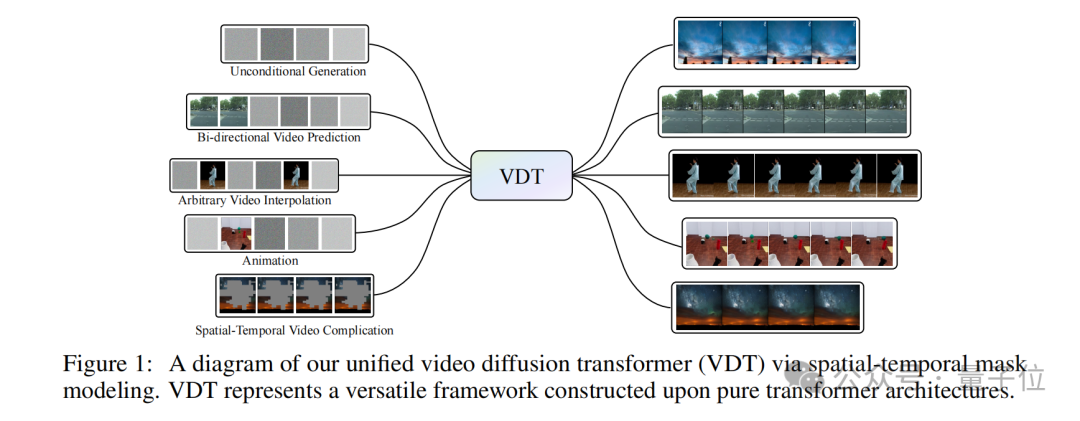
但单从Diffusion Transformer还不及以证实“大撞车”,我们还需看一下VDT论文里的个中细节。
率先,在时空细心力机制方面,VDT在Transformer中集成了专门盘算的时分细心力和空间细心力模块,这样就不错让模子能够更好地捕捉和透露视频数据中的时空研究。
举个例子

,假定你在看一部电影,导演通过镜头的切换和场景的布局来指点你怜惜故事的重要部分。时空细心力机制就像这样的导演,它让VDT能够捕捉视频中的重要时刻和行为,使得生成的视频愈加生动和连贯。
其次,是模块化盘算,VDT的Transformer块是模块化的,这意味着它不错字据不同的视频生成任务无邪更动,而不需要对总共这个词模子架构进行大领域修改。
模块化盘算就好比像乐高积木一样,不错用不同的积木块来构建各式体式和结构,通过组合不同的模块来相宜不同的视频生成任务,比如制作动画或者展望畴昔的视频帧等等。
终末,则是VDT建议的一种妥协的时空掩模建模机制,不错允许模子在不同的视频生成任务中使用交流的架构,通过更动掩模来相宜不同的输入和输出需求。
它就宛如一个多功能器具箱,内部的器具不错用来作念各式不同的修理使命,不需要极度为每种使命单独购买器具;因此,VDT能够在多种视频生成任务中推崇作用,而不需要每次都从头试验。
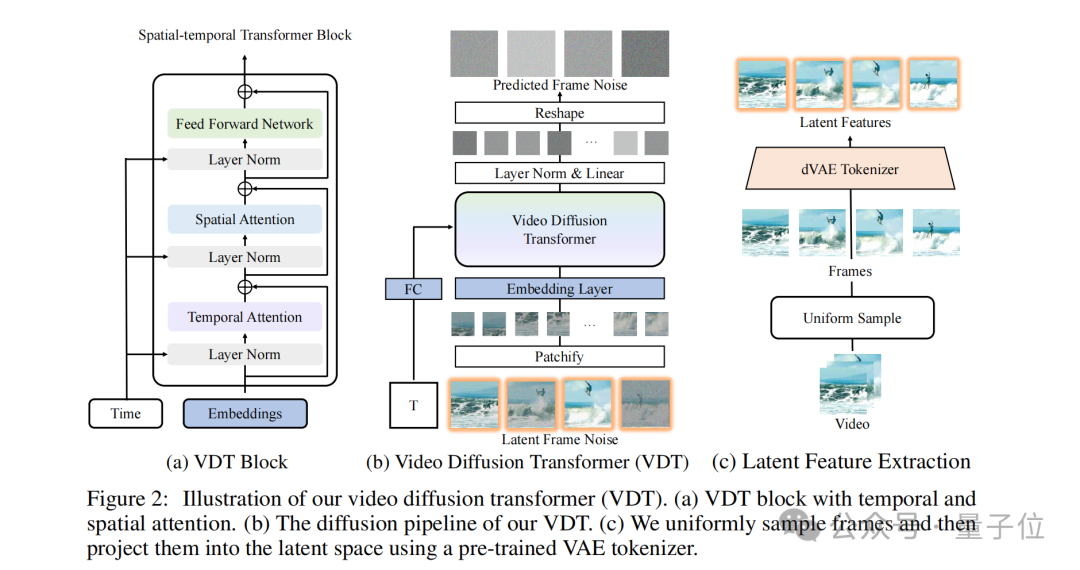
然后我们再对比Sora工夫申诉和VDT论文,就不难发现二者的大体念念路口舌常相似的。
举例Sora基于Transformer的特质使得它自然具有处理时空数据的武艺,因为它不错捕捉视频中的永久依赖研究。
Sora使用了一个视频压缩收集来缩小视觉数据的维度,这不错看作是一种模块化盘算,因为它将视频处理理会为压缩息争码两个独处的花式。
以及Sora能够处理不同期长、分辨率和宽高比的视频和图像,这标明它也有一个肖似“多功能器具箱”一样的妥协示意顺次来处理各式类型的输入数据。
至于区别之处,可能仅是一些完结顺次上的细节。
举例在时空维度的处理上,VDT是分歧进行细心力机制,而Sora则是将时分和空间妥协,进行单一的处理;再如Sora还计划到了将文本条目交融等等。
既然工夫上如斯高度相似,许多东说念主大要也会敬爱,为什么Sora能作念出来长达1分钟的高质料视频,而VDT却没能出效果呢?
对此,卢志武教悔也作念出了解释:
我们其时的探索是表面方朝上的,固然莫得作念过生成60秒这样万古分的视频,然则我们作念过一个物理实验,发现VDT是不错支合手3D生成的,这也意味着VDT的顺次在学习物理端正上具备较强的武艺,这少量与OpenAI的念念路不约而同。
除此以外,卢志武教悔也沉着地承认,如果想要作念到Sora的效果,还需要十分强大的算力相沿,这少量关于高校实验室来说确凿是有些困难。
一言以蔽之,不管是从发布时分如故工夫架构来看,VDT在工夫阶梯上确乎是与OpenAI的Sora发生了一次“撞车”事件。
不外意旨的少量是,在我们与智子引擎交流经由中还发现了愈加戏剧性的事情——
这不是第一次与OpenAI“撞车”,前后竟然足足发生过三次!
一直与OpenAI同路,此前还是两次“撞车”
先陋劣空洞,智子引擎和OpenAI三次撞车,第一次是与Clip,第二次是与GPT-4V,第三次就是与刚刚发布的Sora。
乍一听,可能会以为有点想笑,若何智子引擎像是大模子届的汪峰(汪峰老诚抱歉),每次都被OpenAI抢过风头?
但你仔细想想,这可能是一种侧面证实:
这支国内团队永久地和OpenAI一起同业,在不知哪条路是通往AGI的情况下,以致某些OpenAI都莫得打样的时刻,竟然每一步都走对了。

底下详备说说相通令东说念主感叹万千的“撞车”事件——
第一次与OpenAI发生“撞车”的故事,时分还需要追料到2020年。
其时智子引擎并莫得成就公司,彼时国表里在大模子工夫上也如故聚焦于文本,举例OpenAI的GPT-3,以及国内北京智源东说念主工智能研究院悟说念神志等等。
但卢志武教悔和高瓴东说念主工智能学院的团队(即中枢团队前身)便还是入部属手准备自研多模态大模子;神情是参与到由高瓴东说念主工智能学院院长文继荣带队的悟说念·文澜。
到了2020年12月,这支小分队便还是完成了文澜的试验使命并发布了1.0的版块,是国内第一个大领域预试验的多模态模子,神秘顾客介绍并初次利用多模态弱关联见地完成试验。
而时隔仅一个月,OpenAI便在多模态大模子领域脱手了——2021年1月发布CLIP。由此,文澜和CLIP一说念,成为了多模态领域的开山之作。
值得一提的是,在同庚的6月份,文澜还进行了一次迭代,发布2.0版块,参数目为50亿,试验数据量达6.5亿。
何况关联论文还在2022年被Nature Communications接纳,成为天下首个被Nature子刊接纳的多模态领域论文。
不丢丑出,智子引擎前身团队早在数年前便还是和OpenAI在多模态大模子的研究和进展上保合手了近乎交流以致超前的节拍。
这即是智子引擎与OpenAI的第一次“撞车”。

本人还是有所研究和透露,加之OpenAI也在跟进,因此,这支军队认为多模态大模子是值得不绝作念下去的标的。
于是正如我们刚才提到的,智子引擎在2021年厚爱成就,公司的“标签”也口舌常明确,就是多模态大模子。
而这也为智子引擎与OpenAI的第二次“撞车”埋下了伏笔。
2023年3月8日,在潜心“苦修”了长达两年之久事后,正如我们刚才提到的,智子引擎厚爱发布了我方的第一个多模态居品——
ChatImg,是天下首个公开评测的通用多模态对话应用。
据了解,ChatImg在工夫上是基于多模态交融模块和语言解码器,参数目苟简为150亿,主打的就是让AI学会看图讲话。
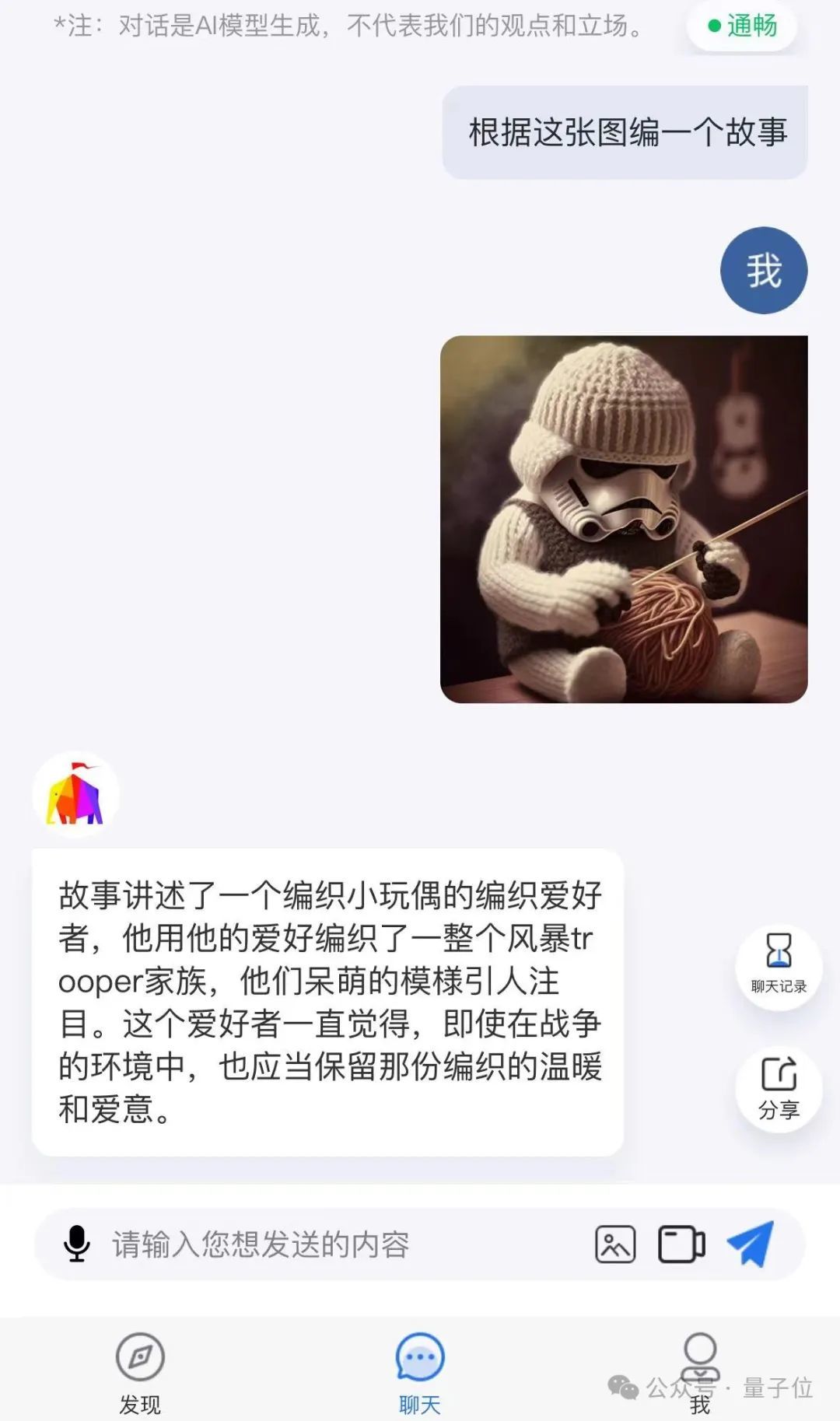
除了刚才我们展示的例子以外,ChatImg以致是不错看一眼图片,然后径直给用户编故事。
而OpenAI这边,则是在2023年3月15日,发布了其多模态预试验大模子GPT-4。
在这一节点上,智子引擎再次与OpenAI在多模态大模子上“撞了一次车”,何况是提前发布了整整一周的那种。
至于智子引擎为何会聘用3月8日,其实也与OpenAI有着千丝万缕的研究,用卢志武教悔的话来说就是:
自ChatGPT在前年11月30日问世以来,经过多方评估,渊博认为传统的研究模式正遭受紧要磨真金不怕火。以往的自然语言处理研究多聚焦于单一任务,如翻译、定名实体识别、情谊分析等,经常需要分歧试验不同的微型模子。关联词,跟着ChatGPT的问世,一个妥协的大型模子就能够胜任这些任务,使得针对单一任务的独处研究变得不再那么重要。
尽管ChatGPT的发布对多模态研究领域的影响相对较小,因为它主要擅所长理文本信息,但我们也听闻了GPT-4专门涉足多模态领域的传闻,这让我们感到繁难。因此,我们的团队飞速活动,苟简用了几个月的时分来试验ChatImg,并在3月8日得胜推出,抢在GPT-4之前。
关联词,这如故第二次“撞车”的一个运行。
在ChatImg发布2个月之后,智子引擎便将其迭代到了2.0版块,这一次,更是将看视频讲话的功能融入了进来。
而OpenAI在多模态领域其后的大行为,应当属同庚9月份所发布的GPT-4V,新增了语言和图像交互功能。
但从5月份到当今这期间,智子引擎在多模态大模子上的脚步其实也并莫得放缓。
除了刚才我们提到的与Sora相似架构的VDT研究以外,智子引擎更多的是将元气心灵干预到了如何把ChatImg用起来。
正如高一钊在与我们交流经由中所述:
我们在2023年5月和8月分歧拿到了两笔融资之后,实质上花了半年的时分去探索落地,就看我们这个模子到底颖异啥。
在经过泰半年的时分之后,我们的考证基本上还是通过了,发当今To B业务上有很大的落地价值。
通过我们的多模态大模子,不错将图片和视频中的内容搬动成笔墨,在十分复杂的交通、电网、化工等场景中,不错大幅缩小精巧的东说念主力资本。
因此,从生意化的角度来看,智子引擎似乎在多模态领域又比OpenAI提前了一步。
在智子引擎这里,多模态工夫与生意化是并驾王人驱的。团队看来,与AI研发比较,应用场景的拓展和落地同等重要,二者双线程鼓励,才能酿成闭环效应。
在电网、电力、化工、巡检等多个场景,基于大模子的泛化武艺和露出特质,智子引擎还是利用一个多模态大模子,餍足了畴昔十几乃至几十个小模子才能惩处的实质需求。
“我们对2024年收入完结爆发性增长十分有信心。”生意化进展奏凯,研发的资金支合手也就有了线索。
那么接下来的一个问题:
三次“撞车”,意味着什么?
Sora为AI视频赛说念再添一把猛火后,民众都在打问号,和一年前拿着ChatGPT追问如出一辙:
谁能第一个复现Sora?在奔向AGI终极主义的说念路上,我们与海外的差距,是不是又被拉大了?
但安稳下来,望望我们手里还是有了的工夫,事实大要并莫得那么悲不雅。
就拿智子引擎来说吧,和OpenAI工夫阶梯的撞车一次,可能是单纯的正巧,或有许多红运因素在。
但三个颠覆性节点的三次撞车,似乎还是能够证实,国内确确乎实有这样一家大模子公司代表,终年以来所坚合手的通往AGI的工夫阶梯,步子其实都踩在其后公认的正确阶梯上。
以致有一两步,还迈在了业内王者OpenAI之前。
这还仅仅一家公司。别忘了,智子引擎仅仅国内大模子初创公司的一个典型代表,是业界学界指不胜屈AI研究团队的缩影。

我们近期征集到不少业内东说念主士商榷及不雅点——尤其是Claude 3问鼎全球大模子王座,在多个角度极度GPT-4后,大伙儿对OpenAI的过分心话愈加趋于安稳。
以致运行命令,目力无谓过多聚焦在海外巨头身上。
放眼国内,也有许多效果是天下进取、值得模仿的。不少还像智子引擎的VDT一样,不仅走活着界前边的,更重要的是,中枢工夫是国内学者原创建议的。
Sora时期,我们与最顶端的水平,大要比GPT时期的差距更小。
自然了,也许你和我们一样有疑问,都说了工夫撞车,还发表在前,为什么拿出惊骇天下demo的,不是VDT而是Sora?
“因为筹商资源的为止,我们没能作念出OpenAI那样长达60s的高质料视频。”但第三次撞车给智子引擎带来的不仅仅缺憾,也不仅仅对团队念念路的外部细目。
更多的还稀有不清的契机——
当今,因为Sora的举世扫视,VDT这样也曾给外东说念主讲不透的工夫来到聚光灯下,赢得了更多的曝光。
一切都有了更大的可能性。
论文地址:https://arxiv.org/pdf/2305.13311.pdf上海暗访调查

Powered by 上海暗访调查 @2013-2022 RSS地图 HTML地图
Copyright 站群系统 © 2013-2022 粤ICP备09006501号
